fedRBE
Getting started with federated limma remove batch effect (fedRBE)
This guide is designed for beginners who want a quick and easy way to start using fedRBE and test its functionality.
For more technical details and advanced usage and specific implementation details, please refer to the app README.
fedRBE allows you to remove batch effects from data in a federated manner, ensuring data privacy.
For a more formal description and details, see the fedRBE’s preprint on ArXiv.
List of contents
- Minimal requirements and setup
- Understanding the workflow
- File preparation
- Step-by-step scenario
- Results and output
- Single-machine simulations using the provided sample data
- Troubleshooting tips
Minimal requirements and setup
Ensure you have the following installed before starting:
- Docker: Installation Instructions
- Python 3.8+: Installation Instructions
- FeatureCloud CLI:
pip install featurecloud - FeatureCloud account: Register at featurecloud.ai and obtain coordinator/participant tokens.
For Windows users, we recommend using WSL.
Understanding the workflow
Below is a simplified workflow of how to use fedRBE:
- Coordinator creates a FeatureCloud project and distributes tokens to at least 3 participants.
- Each Participant (Client) prepares their data and a
config.ymlfile. - All Clients join the project using FeatureCloud and run the app locally.
- fedRBE aligns and corrects batch effects without sharing raw data.
- Results are produced locally at each client, ensuring privacy.
File preparation
You need two main inputs:
- Expression Data File (CSV/TSV)
config.ymlfor custom settings- and Optional Design File with covariates (if needed).

Minimal Example Directory Structure:
client_folder/
├─ config.yml
├─ expression_data.csv
├─ design.csv
If you want to simulate a federated workflow on a single machine, you can use the provided sample data and test script. In this case, you need to create at least three folders, each with the sample data and a config.yml file (for example, clientA, clientB, clientC folders).
Example config.yml snippet:
flimmaBatchCorrection:
data_filename: "expression_data_client1.csv"
expression_file_flag: False # True if data is in samples x features format
index_col: "GeneIDs" # Column name to use as index
covariates: ["Pyr"] # Covariates column name to include in the design matrix
separator: "," # Separator used in the data file
design_separator: "," # Separator used in the design file
normalizationMethod: "log2(x+1)" # Normalization method or log transformation
smpc: True # Recommended to set to True
min_samples: 2 # Minimum number of samples to include a feature
position: 1 # position of the client (first, second, third, etc.)
reference_batch: "" # if True, this client is used as the reference batch
For more details on the config.yml parameters, see the app README.
Step-by-step scenario
Scenario: Three clients (A, B, and C) collaborate on a federated analysis. Video tutorial: FeatureCloud tutorial.
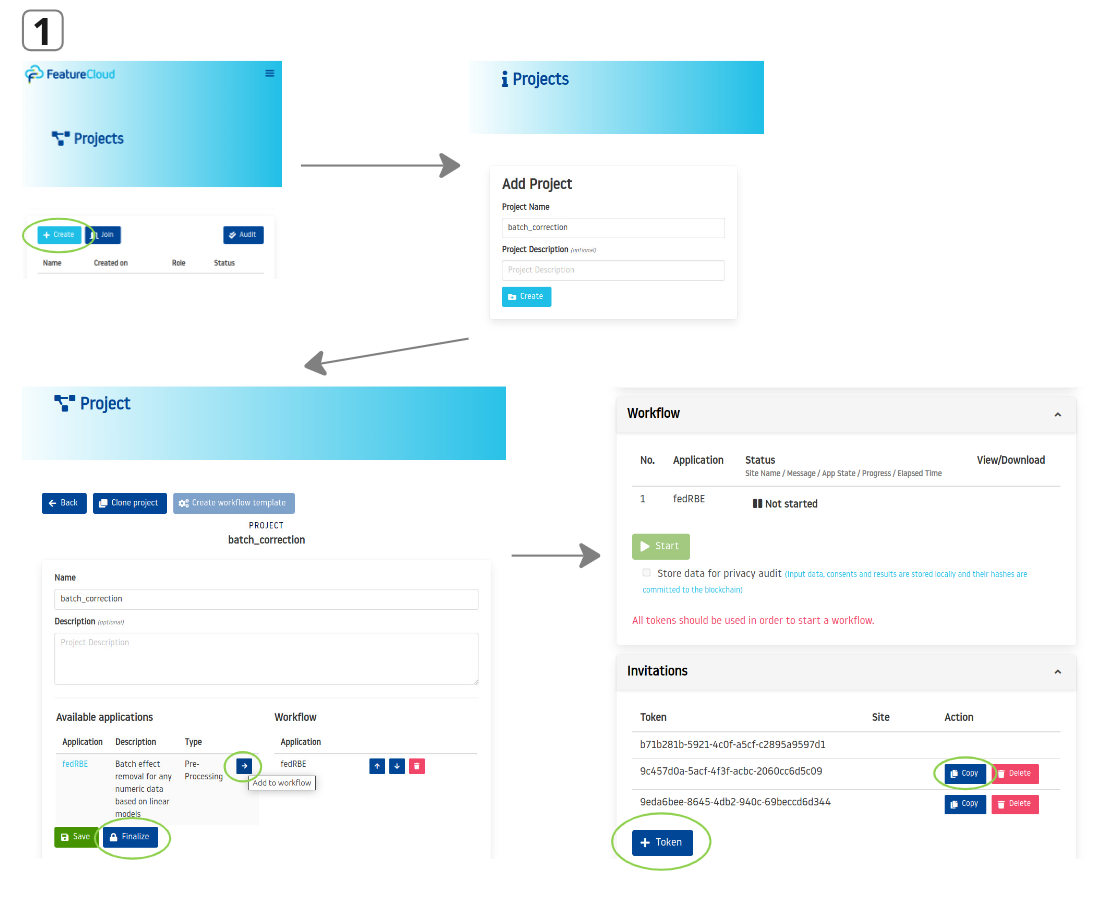
- Coordinator Actions:
- The coordinator logs into the FeatureCloud platform and creates a new project.
- Add the fedRBE app into the workflow and finalize the project.
- The coordinator creates tokens and sends them to Clients A, B, and C.
- Client Setup:
- Client A, B, C: Place
expression_data_client.csvandconfig.ymlin a local folder. - Adjust
config.ymlparameters as needed (e.g., changedata_filenameto match the correct file name). - In case of multiple batches in one client, the client should provide a
design.csvfile with batch information and specify this column name in theconfig.ymlparameterbatch_col.
- Client A, B, C: Place
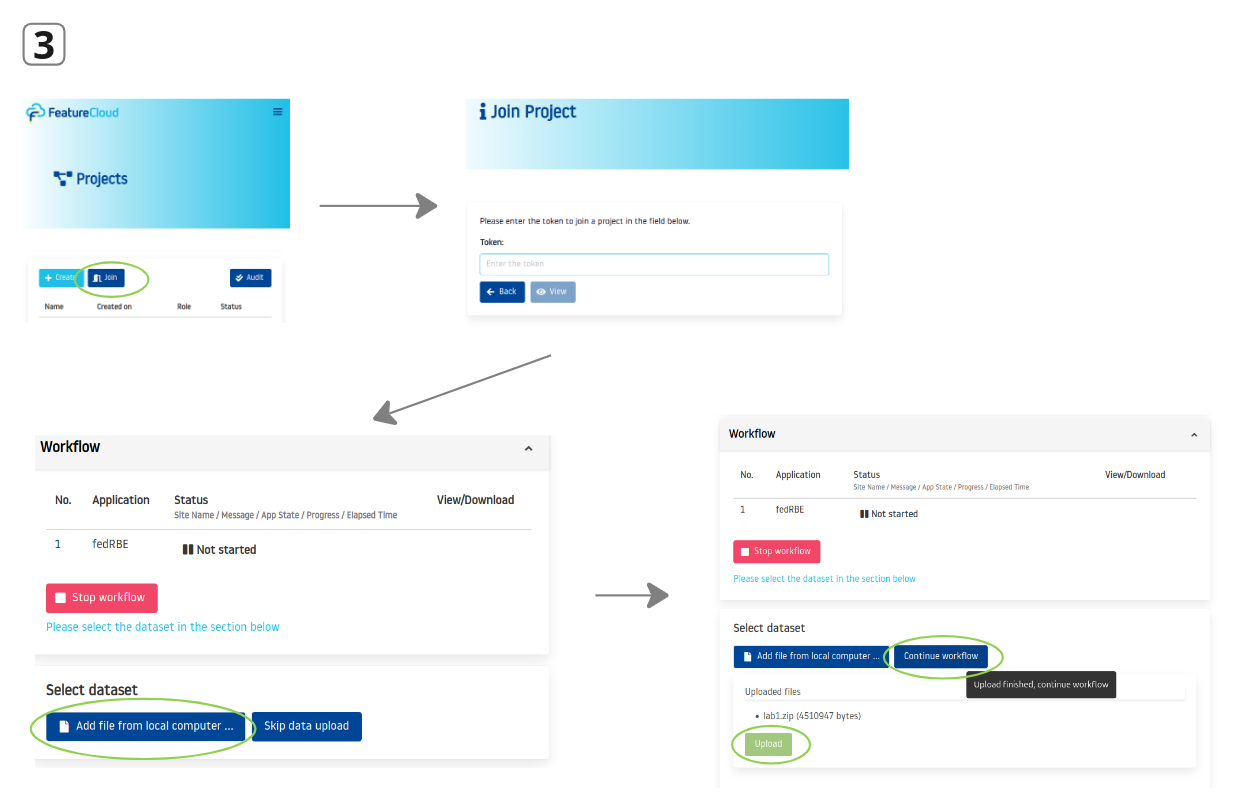
- Joining the Project:
- Each client uses the FeatureCloud to login and join the project using the provided token.
- After joining, each client uploads their data and config file to the FeatureCloud GUI client as a one .zip file (without any folder structure inside). It will not be sent to the coordinator or other clients, but makes it available for the Docker container with the app.
- Running fedRBE:
- After all clients join, the coordinator starts the project.
- The app runs locally at each client, securely combining results.
Results and output
After completion, each client finds:
only_batch_corrected_data.csv: The batch-corrected expression data.report.txt: Details on excluded features, beta values, and the used design matrix.- logs: Detailed logs of the process.
Single-machine simulations using the provided sample data
If you’d like to test everything on one machine, you can run the provided sample data and test script. This simulates multiple clients locally, so you can see the federated workflow in action without needing multiple machines.
For instructions, see the Local Test Simulation guide.
Troubleshooting tips
- Missing Files: If you see “file not found,” ensure that
config.ymland data files are in the same directory. - Incorrect Format: Check if
expression_file_flagandindex_colare set correctly based on your data orientation. - No Output Produced: Review
report.txtand logs. - Errors with Test runs: Ensure the is no leftover running Docker containers. Restart Docker / System if necessary.
Choosing the correct data orientation
Depending on how your data is structured, you must correctly set expression_file_flag in your config.yml:
-
If your file is features (rows) x samples (columns):
expression_file_flag: Trueandindex_col: <feature_id_column> -
If your file is samples (rows) x features (columns):
expression_file_flag: Falseandindex_col: <sample_id_column>
Incorporating covariates
If you have additional covariates (e.g., age, treatment type) that might influence your data, you can include them either directly in the design_filename file or list them in your config.yml under covariates. If no separate design file is provided, these covariates must exist as features in the main data file.
Example:
covariates: ["Age", "Treatment"]
Selecting a reference batch
fedRBE needs a reference batch to align the other batches against. By default, if no reference_batch is set, it uses the last client in the positional order defined by the position parameter. If all parameters are unset, it may choose a batch at random, resulting in non-deterministic runs.
Example:
position: 2
reference_batch: ""